Wide and Deep Models
Google play recommendations use a wide and deep modeling approach according to Heng-Tze Cheng, Levent Koc et al.. The basic idea is that memorization of co-occurence for app installs is very powerful when there is a clear signal but that it is hard for new applications and doesn’t generalize well. Use a deep learning model of more primitive features (e.g. words, category, etc.) to get better generalization and combine with memorization to get something like the best results from each.
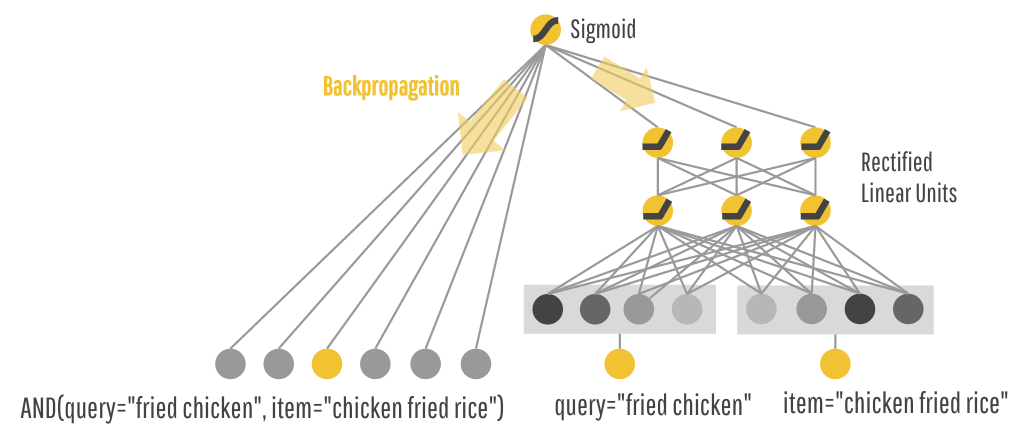
One odd bit of notation for me was their cross-product transformation which seems a bit heavy for just saying that $\boldsymbol{x}$ is in cross $k$
$$ \phi_k(\boldsymbol{x}) = \prod_{i=1}^d x_i^{c_{ki}} \; \; \; c_{ki} \in \{0,1\} $$For experiments they used a follow-the-regularized-leader (FTRL) update rule with $L_1$ regularization for wide part of model and AdaGrad for the deep part (wonder if they tried Adam or other optimizers).
$$ P(Y=1|\boldsymbol{x}) = \sigma(\boldsymbol{w}_{wide}^T[\boldsymbol{x},\phi(\boldsymbol{x})] + \boldsymbol{w}\_{deep}^T a^{(l_f)} + b) $$“Trained over 500 billion examples” guess they have enough training data. This is their ranking layer, they get $O(100)$ candidates and rank down to $O(10)$ in 10 milliseconds (is that P50 10ms or P99 10ms?). Modest 0.006 improvement in AUC over control of just wide.
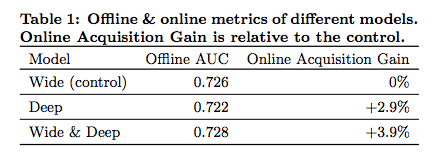
Honestly for the amount of work that went into this I was expecting a bigger increase in performance. They are arguing for a whole new approach to models that would likely be a big infrastructure cost and it looks like they are getting just a little improvement over the individual components.
Two follow up questions that will be in the back of my brain for rest of day.
- I was surprised that the authors didn’t do a comparison explicitly on new content or hide some memorization data from the algorithm and see how it recovered using the deep portion. The overall argument is that this should both generalize and memorize well and since most installs are going to rely on the memorization portion looking at the new/rare rankings should highlight the strengths of this approach. Wonder if it didn’t actually generalize that much or if it did and they just didn’t want to talk about it.
- I also can’t help but wonder if there is some way to better expose the uncertainty or amount of information that a given portion of the network is based on. Perhaps that is just built into the model in terms of low initial counts mean low values on the wide portion of the network?
Overall a very cool paper and big kudos to the authors for releasing their tensorflow code so we can all go try it out!